4.1
ODBC
(Conectividad
abierta de bases de datos)
INTRODUCCIÓN
ODBC logra la independencia DBMS utilizando
un controlador ODBC como una capa de traducción entre la aplicación y el DBMS.
La aplicación utiliza funciones ODBC a través de un gestor de controladores
ODBC con el que está vinculado, y el conductor pasa la consulta al DBMS. Un
controlador ODBC puede ser pensado como análogo a una impresora u otro controlador,
que proporciona un conjunto estándar de funciones para la aplicación a
utilizar, y la aplicación de la funcionalidad de DBMS específico. Una
aplicación que puede utilizar ODBC se conoce como "ODBC". Cualquier
aplicación compatible con ODBC puede acceder a cualquier DBMS para el que se
instala un controlador. Existen controladores para todos los principales DBMS,
muchas otras fuentes de datos, como la libreta de direcciones sistemas y
Microsoft Excel, e incluso para el texto o CSV archivos.
ODBC fue desarrollado originalmente por
Microsoft durante la década de 1990, y se convirtió en la base para la Interfaz
de nivel de llamada (CLI) estandarizada por SQL Access Group en Unix y
mainframe de mundo. ODBC mantiene una serie de características que se han
eliminado como parte del esfuerzo de CLI. Completo ODBC más tarde fue portado
de nuevo a esas plataformas, y se convirtió en un estándar de hecho
considerablemente más conocido que CLI. El CLI sigue siendo similar a ODBC, y
las aplicaciones pueden ser portado de una plataforma a la otra con pocos
cambios.
Definición:
Es un estándar de lenguaje de programación C middleware API para
acceder a los sistemas de gestión de bases de datos (DBMS). Los diseñadores de
ODBC dirigidos para que sea independiente de los sistemas de bases de datos y
sistemas operativos, una aplicación escrita utilizando ODBC puede ser portado a
otras plataformas, tanto en el lado del cliente y el servidor, con pocos
cambios en el código de acceso a datos.
Objetivo:
El objetivo de ODBC es hacer posible el
acceder a cualquier dato desde cualquier aplicación, sin importar qué sistema
de gestión de bases de datos (DBMS) almacene los datos. ODBC logra esto al
insertar una capa intermedia (CLI) denominada nivel de Interfaz de Cliente SQL,
entre la aplicación y el DBMS.
Características:
- La conectividad de datos para aplicaciones Web y aplicaciones server críticas más escalable y confiable. Connect ODBC 3.5 soporta Microsoft Transaction Server para Oracle 8, SQL Server 7, y los sistemas de bases de datos Sybase Adaptive Server 12.
- Es el primer y único ODBC driver para conectividad directa desde aplicaciones UNIX hacia Microsoft SQL Server – Este nuevo soporte permite a las organizaciones desarrollar o desplegar sus datos SQL Server para cliente/servidor y aplicaciones basadas en el Web residiendo sobre UNIX. Cursor scrollable es soportado para todas las bases de datos. Del mismo modo muchas bases de datos y ODBC drivers no soportan cursores de éste tipo. Con Connect ODBC 3.5 usted obtiene soporte para todas sus aplicaciones de ODBC.
- DataDirect Connect ODBC libera el ODBC driver para aplicaciones en plataforma Irix y bases de datos como Informix y Sybase.
¿Cómo se
procesa ODBC?
Para usar el ODBC, tres componentes son
necesarios: cliente ODBC, el controlador ODBC, DBMS y un servidor (por ejemplo,
Microsoft Access, SQL Server, Oracle, y FoxPro). En primer lugar, el cliente
ODBC utilizará un comando (denominado “ODBC”) para interactuar (solicitante y /
o envío de datos) con el servidor DBMS (back-end). Sin embargo, el DBMS
servidor no entender el comando de la ODBC cliente aún, como el comando todavía
no se ha procesado a través del controlador ODBC (front-end). Entonces, el
controlador ODBC se decodificar el comando que puede ser procesado por el
servidor ODBC y ser enviados allí. El servidor ODBC entonces en contacto con el
controlador ODBC que se encargará de traducir el producto final al cliente
ODBC.
ODBC asegura una conexión continua desde un
cliente, servidor o aplicaciones Web. ODBC provee una solución completa e
independiente para el acceso a datos, porque define estándares para el proceso
y acceso físico a las bases de datos. ODBC permite a las aplicaciones cliente
desarrollar en una única y común API.
Casi todas las DB actuales tienen un ODBC.
Debido a que este elemento impone ciertas limitaciones, ya que no todo lo que
la DB sabe hacer es compatible con la aplicación, como velocidad de proceso,
tiempos de espera, máxima longitud de registro, número máximo de registros,
versión de SQL, etc., está cayendo en desuso a cambio de otras técnicas de
programación, pero aún le quedan muchos años de buen servicio.
Plataformas
en las que se utiliza
La tecnología ODBC es utilizada en múltiples
plataformas, incluyendo Windows 3.1, Windows NT, OS/2, Macintosh y UNIX, y
DBMS´s como DB2, Oracle, SYBASE, INFORMIX, Microsoft SQL Server, DEC, Apple
DAL, dBase, Excel, etc.
Funcionamiento:
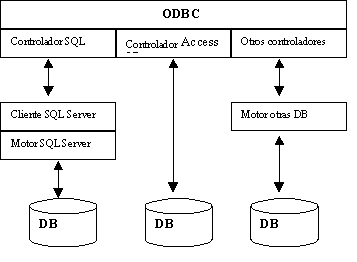
ODBC es una API que permite a las
aplicaciones acceder a datos de muchos sistemas de gestión de bases de datos. ODBC ofrece a las
aplicaciones cliente un lenguaje común para interactuar con fuentes de datos y servicios de base de
datos.
4.2 ADO.NET.
INTRODUCCIÓN
ADO.NET responde a las siglas de Microsoft
ActiveX Data Objects de la plataforma.NeT y es una mejora evolutiva de la
tecnología ADO. Realmente es una evolución más en las tecnologías de acceso a
la información.
ADO.NET forma parte del tercer nivel del
conjunto de objetos que el .NET Framework ofrece para trabajar dentro de esta plataforma, junto con XML constituyen un
subgrupo específico que están preparados para manejar datos. Al igual que el resto de los elementos que constituyen
el .NET Framework se estarán ejecutando dentro del Motor de Ejecución Común o CLR y está formado por un
conjunto de clases administradas organizadas en espacios de nombre.
ADO.NET proporciona acceso coherente a
orígenes de datos como Microsoft SQL Server, así como a orígenes de datos expuestos mediante OLE DB y XML (Microsoft
Access, Microsoft Visual FoxPro, etc.). Las aplicaciones para usuarios que comparten datos pueden utilizar ADO.NET
para conectarse a estos orígenes de datos y recuperar, manipular y actualizar los datos.
ADO.NET separa limpiamente el acceso a datos
de la manipulación de datos y crea componentes discretos que se pueden usar por separado o conjuntamente.
ADO.NET incluye proveedores de datos de .NET Framework para conectarse a una base de datos específica,
ejecutar comandos y recuperar resultados. Esos resultados se procesan directamente
o se colocan en un objeto DataSet (repositorio en cliente) de ADO.NET con el
fin de exponerlos al usuario para un propósito específico, junto con datos de
varios orígenes, o de utilizarlos de forma remota entre niveles. El objeto
DataSet de ADO.NET también puede utilizarse independientemente de un proveedor
de datos de .NET Framework para administrar datos que son locales de la
aplicación o que proceden de un origen XML.
ADO.NET fue diseñado para tener un acceso
desconectado a la base de datos. En principio en ADO.NET se puede modelar la
estructura de una base de datos desde el código sin necesidad de acceder a una
base de datos existente.
Es un conjunto de componentes del software
que pueden ser usados por los programadores para acceder a datos y a servicios
de datos. Es una parte de la biblioteca de clases base que están incluidas en
el Microsoft .NET Framework. Es comúnmente usado por los programadores para
acceder y para modificar los datos almacenados en un Sistema Gestor de Bases de
Datos Relacionales, aunque también puede ser usado para acceder a datos en fuentes
no relacionales. ADO.NET es a veces considerado como una evolución de la
tecnología ActiveX Data Objects (ADO), pero fue cambiado tan extensivamente que
puede ser concebido como un producto enteramente nuevo.
Las principales características:
- Trabaja desconectado del origen de datos que se utilice.
- Tiene una fuerte integración con XML y ASP.NET.
- El uso de ADO.NET es independiente del lenguaje de programación que se utilice.
La
tecnología ADO.NET está basada en un nuevo modelo de componentes en la que las
clases de acceso a datos y las clases contenedores forman parte del marco de
trabajo de. NET sobre todo ADO.NET está pensado para ”interoperar” con otros
componentes, sistemas ,etc. Gracias al uso de XML y a soportar estándares como
HTTP, XML, o SOAP.
El modelo de
ADO.NET está dividido en dos grupos:
- Los proveedores de datos o Mnaged Data Providers.
- Los contenedores de datos, que aunque están vinculados a los orígenes de datos, son independientes de ellos.
ADO.NET evolucionó de la tecnología Microsoft
ActiveX Data Objects (ADO), que proporciona acceso a datos independientemente
de la plataforma. La ventaja básica de la arquitectura ADO.NET es que permite a
los desarrolladores manipular datos sin importar la ubicación de los mismos.
Arquitectura :

La pieza central de cualquier solución de
software usando ADO.NET es el Dataset. Un Dataset es una copia en la memoria de
los datos de la base de datos. Un Dataset puede contener datos de cualquier
cantidad de tablas o vistas de bases de datos. El Dataset constituye una vista
desconectada de la base de datos porque existe en la memoria sin una conexión
activa a una base de datos que contenga las tablas o vistas correspondientes.
Esta arquitectura desconectada permite una mayor escalabilidad solamente con
usar los recursos del servidor de la base de datos cuando se lean o escriban desde
la base de datos.
La ventaja más grande de utilizar un Dataset
es que proporciona una vista de la base de datos con varias tablas y sus
relaciones, todas sin tener una conexión activa a la base de datos. Puede
pensar en un Dataset como una base relacional miniatura dentro de la memoria.
Normalmente, se crea un Dataset y se llena de manera programática. Contiene
varias tablas, cada una de las cuales corresponde a una tabla o vista de la
base de datos.
La ventaja más grande de utilizar un Dataset
es que proporciona una vista de la base de datos con varias tablas y sus
relaciones, todas sin tener una conexión activa a la base de datos. Puede
pensar en un Dataset como una base relacional miniatura dentro de la memoria.
Normalmente, se crea un Dataset y se llena de manera programática. Contiene
varias tablas, cada una de las cuales corresponde a una tabla o vista de la
base de datos.
En aplicaciones con n niveles, normalmente
los datos se pasan desde la base de datos a un objeto de negocios de nivel
medio y luego a la interfaz. Para acomodar el intercambio de datos, ADO.NET usa
un formato de persistencia y transmisión con base en XML. Es decir, para
transmitir datos de un nivel a otro, una solución ADO.NET expresa los datos en
memoria (el Conjunto de datos) como XML y después envía el XML a otro
componente.
componentes
principales de una solución ADO.NET

La arquitectura ADO.NET aprovecha XML. Debido
a que XML es el formato para transmitir datos, cualquier aplicación Web que
pueda leer el formato XML puede procesar datos.
ADO.NET
consiste en dos partes primarias:
Data provider
Estas
clases proporcionan el acceso a una fuente de datos, como Microsoft SQL Server y Oracle. Cada
fuente de datos tiene su propio conjunto de objetos del proveedor, pero cada
uno tienen un conjunto común de clases de utilidad:
- Connection: Proporciona una conexión usada para comunicarse con la fuente de datos. También actúa como Abstract Factory para los objetos command.
- Command: Usado para realizar alguna acción en la fuente de datos, como lectura, actualización, o borrado de datos relacionales.
- Parameter: Describe un simple parámetro para un command. Un ejemplo común es un parámetro para ser usado en un procedimiento almacenado.
- DataAdapter: "Puente" utilizado para transferir data entre una fuente de datos y un objeto DataSet .
- Data Reader: Es una clase usada para procesar eficientemente una lista grande de resultados, un registro a la vez.
DataSets
Los
objetos DataSets, es un grupo de clases que describen una simple base de datos relacional en memoria, fueron la estrella del show en el lanzamiento inicial (1.0)
del Microsoft .NET Framework. Las clases forman una jerarquía de contención:
·
Un objeto DataSet representa un esquema (o una base de
datos entera o un subconjunto de una). Puede contener las tablas y las relaciones
entre esas tablas.
·
Un objeto DataTable representa una sola tabla en la base
de datos. Tiene un nombre, filas, y columnas.
·
Un objeto DataView "se sienta sobre" un
DataTable y ordena los datos (como una cláusula "order by" de SQL) y,
si se activa un filtro, filtra los registros (como una cláusula
"where" del SQL). Para facilitar estas operaciones se usa un índice
en memoria. Todas las DataTables tienen un filtro por defecto, mientras que
pueden ser definidos cualquier número de DataViews adicionales, reduciendo la
interacción con la base de datos subyacente y mejorando así el desempeño.
·
Un DataColumn representa una columna de la tabla,
incluyendo su nombre y tipo.
·
Un objeto DataRow representa una sola fila en la tabla,
y permite leer y actualizar los valores en esa fila, así como la recuperación
de cualquier fila que esté relacionada con ella a través de una relación de
clave primaria - clave extranjera.
·
Un DataRowView representa una sola fila de un
DataView, la diferencia entre un DataRow y el DataRowView es importante cuando
se está interactuando sobre un resultset.
·
Un DataRelation es una relación entre las tablas,
tales como una relación de clave primaria - clave ajena. Esto es útil para
permitir la funcionalidad del DataRow de recuperar filas relacionadas.
·
Un Constraint describe una propiedad de la base de
datos que se debe cumplir, como que los valores en una columna de clave
primaria deben ser únicos. A medida que los datos son modificados cualquier
violación que se presente causará excepciones.
Un DataSet es llenado desde una base de datos por un DataAdapter
cuyas propiedades Connection y Command que han sido iniciados. Sin embargo, un
DataSet puede guardar su contenido a XML (opcionalmente con un esquema XSD), o
llenarse a sí mismo desde un XML, haciendo esto excepcionalmente útil para los
servicios web, computación distribuida, y aplicaciones ocasionalmente
conectadas desconectados.
 |
| Clases contenidas en ADO.NET. |
Descripción de las clases:
- XxxConnection: representa una conexión. Almacena, entre otras cosas, el string de conexión (connection string), y permite conectarse y desconectarse con una base de datos.
- XxxCommand: permite almacenar y ejecutar una instrucción SQL contra una base de datos, enviando parámetros de entrada y recibiendo parámetros de salida.
- XxxDataReader: permite acceder a los resultados de la ejecución de un comando contra la base de datos de manera read-only (sólo lectura), forward-only (sólo hacia adelante). Esta clase se utiliza en escenarios conectados, ya que no es posible operar sobre los registros de un DataReader estando desconectado de la fuente de datos.
- XxxDataAdapter y DataSet: en conjunto, estas clases constituyen el corazón del soporte a escenarios desconectados de ADO.NET. El DataSet es una representación en memoria de una base de datos relacional, que permite almacenar un conjunto de datos obtenidos mediante un DataAdapter. El DataAdapter actúa como intermediario entre la base de datos y el DataSet local desconectado. Una vez que el DataSet se encuentra lleno con los datos que se necesitan para trabajar, la conexión con la base de datos puede cerrarse sin problemas y los datos pueden ser modificados localmente. Por último, el DataAdapter provee un mecanismo para sincronizar los cambios locales contra el servidor de base de datos. Nótese que la clase System.Data.DataSet no tiene el prefijo Xxx, ya que es independiente del proveedor de acceso a datos utilizado.
Para empezar una transacción en ADO.NET se
llama al método BeginTransaction que acepta el parámetro IsolationLevel (nivel
de aislamiento) y/o el nombre, y devuelve un objeto transacción de la clase
OleDbTransaction o SqlTransaction dependiendo del proveedor que se utilice.
El objeto SqlTransaction Soporta savepoints o
puntos de almacenamiento de la transacción que permiten deshacerla (RollBack)
más tarde. Para almacenar un savepoint se utiliza el método sabe. Esta
funcionalidad es equivalente a la declaración “SAVE TRANSACTION”que se realiza
en T-AQL.
Si se quiere deshacer una transacción ya
almacenada, ha de utilizarse el método Rollback que puede llevar como parámetro
el nombre del punto de almacenamiento previamente guardado. En caso de querer
aceptar la transacción se utilizará el método commit.
4.3 JDBC
(Java Database Connectivity)
INTRODUCCIÓN(Java Database Connectivity)
El API JDBC se presenta como una colección de
interfaces Java y métodos de gestión de manejadores de conexión hacia cada
modelo específico de base de datos. Un manejador de conexiones hacia un modelo
de base de datos en particular es un conjunto de clases que implementan las
interfaces Java y que utilizan los métodos de registro para declarar los tipos
de localizadores a base de datos (URL) que pueden manejar. Para utilizar una
base de datos particular, el usuario ejecuta su programa junto con la
biblioteca de conexión apropiada al modelo de su base de datos, y accede a ella
estableciendo una conexión; para ello provee el localizador a la base de datos
y los parámetros de conexión específicos. A partir de allí puede realizar
cualquier tipo de tarea con la base de datos a la que tenga permiso: consulta,
actualización, creación, modificación y borrado de tablas, ejecución de
procedimientos almacenados en la base de datos, etc. JDBC no sólo provee un
interfaz para acceso a motores de bases de datos, sino que también define una
arquitectura estándar, para que los fabricantes puedan crear los drivers que
permitan a la aplicación java el acceso a los datos.
Definición:
DBC es un API (Application programming
interface) que describe o define una librería estándar para acceso a fuentes de
datos, principalmente orientado a Bases de Datos relacionales que usan SQL
(Structured Query Language). JDBC no sólo provee un interfaz para acceso a
motores de bases de datos, sino que también define una arquitectura estándar,
para que los fabricantes puedan crear los drivers que permitan a la aplicación
java el acceso a los datos.
JDBC permite que cualquier comando SQL pueda
ser pasado al driver directamente, con lo que una aplicación Java puede hacer
uso de toda la funcionalidad que provea el motor de Base de Datos, con el
riesgo de que esto pueda producir errores o no en función del motor de Base de
Datos.

Transacciones
JDBC permite agrupar instrucciones SQL en una
sola transacción. Así, podemos asegurar las propiedades ACID (Atomicidad,
Consistencia, Aislamiento, Durabilidad) usando las facilidades transaccionales
del JDBC.
El control de la transacción es realizado por
el objeto Connection. Cuando una conexión se crea, por defecto es en modo auto - commit. Esto significa que
cada instrucción individual SQL se trata como una transacción en sí misma, y se
comprometerá en cuanto la ejecución sea terminada. (Esto no es exactamente
preciso, pero podemos encubrir esta sutileza por propósitos didácticos).
Nosotros podemos desactivar el modo auto -
commit para una conexión activa con: con.setAutoCommit(false) ;
y se lo vuelve a activar con:
con.setAutoCommit(true) ;
Una vez que el auto-commit is desactivado,
ninguna declaración del SQL se comprometerá (es decir, la base de datos no se
actualizará permanentemente) hasta que usted le haya dicho explícitamente que
comprometa invocando el método commit():
con.commit() ;
A cualquier punto antes del commit, podemos
invocar un rollback () para reversar la transacción, y restaurar los valores al
último punto de commit (antes de las actualizaciones intentadas).
Aquí hay un ejemplo que presenta estas ideas:
con.setAutoCommit(false);
Statement stmt =
con.createStatement();
stmt.executeUpdate("INSERT
INTO Venta VALUES('El Cantinazo','Rivereña',1000)" );
con.rollback();
stmt.executeUpdate("INSERT
INTO Sells VALUES('Bar Ato', 'Mellir', 1200)" );
con.commit();
con.setAutoCommit(true);
Examinemos el ejemplo para entender los
efectos de varios de los métodos. Primero se declaró desactivar el autocommit,
indicando eso que las siguientes instrucciones necesitaban considerarse como
una unidad. Luego intentamos insertar en la tabla Venta la tupla ('El
Cantinazo','Rivereña',1000). Sin embargo, este cambio no será realizado hasta
el final (cuando se ejecute el commit). Cuando invocamos el rollback, nosotros cancelamos
la anterior inserción y en efecto se elimina cualquier intención de insertar la
tupla anterior. Note que Venta ahora todavía es como era antes de que
intentáramos la inserción. Ahora intentamos otra inserción, y esta vez,
nosotros comprometemos la transacción. Sólo es ahora que Venta se afecta
permanentemente y tiene una nueva tupla en ella. Finalmente, restablecemos la
conexión para realizar de nuevo un auto-commit. También podemos asignar niveles
de aislamiento de la transacción como se desee. Por ejemplo, podemos asignar
el nivel de aislamiento de transacción
en TRANSACTION_READ_COMMITTED, que no permitirá acceder un valor hasta después de que haya sido comprometido
(committed), y puede prohibir las lecturas sucias. Hay cinco que valores para niveles de aislamiento
proporcionados en la interfaz Connection. Por defecto, el nivel de aislamiento
es el serializable. JDBC nos permite definir el nivel de aislamiento de transacción
a la base de datos (usando el método de Connection : getTransactionIsolation )
y asignar el nivel apropiado (usando el método de Connection :
setTransactionIsolation).
Normalmente se usará rollback en combinación
con el manejo de excepciones de Java para recuperar errores predecibles (o no).
Tal una combinación provee un mecanismo excelente y fácil para el manejo de
integridad de los datos.
Instalación de JDBC
El proceso de instalación de JDBC se podría
dividir en tres partes distintas:
- Descargar el API de JDBC:
JDBC viene incluido en el corazón de la
plataforma Java, tanto en la J2SE como en la J2EE.
Versión actual JDBC 1.3 (incluida en J2SE
1.4)
Versión en borrador JDBC 1.4
- Instalar el driver en la máquina cliente (máquina que crea las conexiones)
La instalación del driver dependerá en gran
medida del tipo de driver que hayamos seleccionado.
Para los tipo 1 y 2, además de las librerías
del driver, necesitaremos ciertas librerías propias del cliente del motor de
base de datos que estemos usando y quizá ficheros de configuración...
Para el tipo 3, en la máquina cliente tan
solo necesitaremos el driver. En el servidor donde resida el middleware,
necesitaremos drivers específicos de cada motor de base de datos y en su caso,
librerías propias del cliente del motor de base de datos.
Para el tipo 4, tan solo necesitaremos el
driver.
- Instalar el controlador o motor de base de datos.
Evidentemente, necesitaremos tener instalado
un motor de base de datos. Esta instalación será distinta en función de la Base
de Datos y del S.O donde vaya a correr.
Fuentes Bibliograficas:
http://www.willydev.net/InsiteCreation/v1.0/Desde0/m06/06m3.htm